reserve sort
このコンテンツは、私が、考案したソートのアルゴリズムの説明です。
特徴
- 安定ソート
- データ配列と同じだけの作業用配列が必要
- 計算量オーダーは、O(N×log(N))
同じ特徴を持つマージソートと比べて、取り立てて優秀なアルゴリズムではありませんが、
ランダムなデータでは、若干、速い処理が期待できます。
アルゴリズムの紹介
1.データの中央を基準値にします。

2.基準値より小さいデータ、同じデータ、大きいデータの個数を数えます。
小さいデータ 9
同じデータ 3
大きいデータ 8
3.各データの個数から、それぞれのデータを格納する先頭の位置を計算します
テンポラリー配列

4.配列の先頭からデータを読み、各格納位置へデータをコピーします。
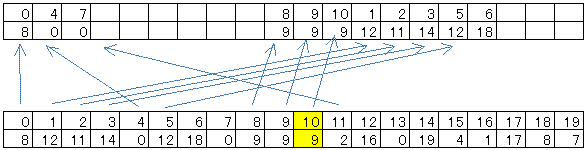
すると、テンポラリー配列上に、基準値を境にして、小さいデータと大きいデータを分けることができます。

5.同じデータに関しては、ソート済みとし、テンポラリー配列に配置されている分は、メインの方にコピーします


小さいデータ、大きいデータの部分に関して再帰的にソートの処理を行います。
今度は、テンポラリー上に配置されたデータを、データ配列に向けてコピーします。
以降、データ配列->テンポラリー配列、テンポラリー配列->データ配列を繰り返す。
※1 未ソート部の個数が1つの場合は、ソート済みと判断します。

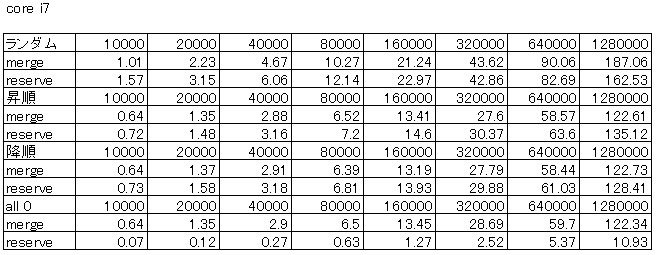
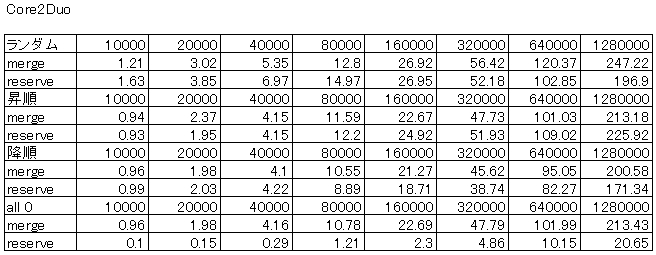
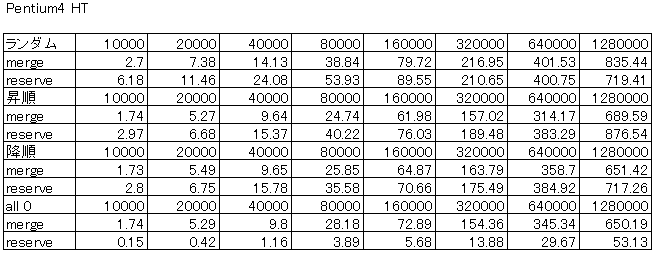
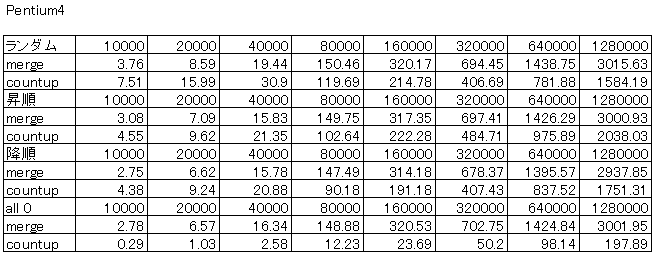
パフォーマンス
Core i7、Core2Duo、Pentium4HT、Pentium4での結果を示します。
ランダム、昇順、降順、all0の各データ配列を生成し、そのソートの所要時間(単位:ms)を示しています。
ソース
ソースのダウンロード
ダウンロードで、得られるものは、ランダムデータを生成し、マージソートと比較するプログラムです。
reserveperformancetest.zip
最後に、このアルゴリズムに対するご意見、特に、既存のアルゴリズムに似ているという情報がありましたら、BBSの方に書き込んでください。
もし、類似性を確認できたら、その旨、加筆します。